
When performing conversions between CAT tools with the objective of obtaining a Trados TagEditor file for translation, it often happens that a source content (original text for translation) gets copied into the target area of the translation unit. Despite deleting the unwanted text is just a matter of a few key presses, it can (and mostly is) annoying when working with large files. Use this simple procedure to get a “clean” TTX file for translation.
Pre-requisites:
- TagEditor file to be cleaned (TTX)
- Notepad2 freeware text editor (download here)
Initial situation:
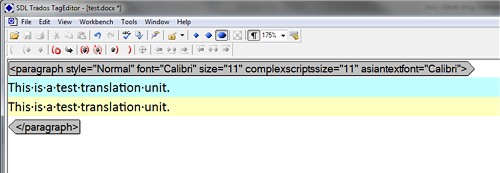
And desired situation
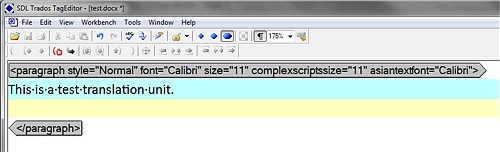
I recommend creating a backup file just in case something goes wrong.
Proceed as follows:
1. Open Notepad2.
2. Open the source TagEditor file (TTX) in Notepad2.
3. Select Edit -> Replace or use Ctrl+H shortcut.
4. Enter this into the Search string field: <Tuv Lang=”XX”>.*?</Tuv>
Note: Do not forget to substitute XX for the target language code. Ex.: CS for Czech.
5. Enter this into the Replace with field: <Tuv Lang=”XX”></Tuv>
Again, substitute XX with the target language code.
6. Check the Regular expression search checkbox.
7. Press the Replace All button.
8. Save the resulting file.
Now you have a clean source TTX file for translation.

Hi!
I did what you wrote, but got “expected end of tag ‘Tu’ ”
Any ideas?
Hi, seems you accidentally deleted the end tag from a TU.
I used this solution many times and it worked for me. However, I do not claim it to be a 100% one.
Restore the original file from backup (you have to make a backup before manipulating files just to make sure you do not end up without any valid data) and try the procedure once again making sure that you use a correct search and replace text.
it does not really makes sense… YOu say to subtitute with target language in the search field and also to subtitute with target language in the replace field!
So in my case, I have both En-US in the target segments… TO if I do a
So if I do as you say, and replace by “FR-FR” every segments will be French, both target and source!
Basically, what you want to do is to remove all texts in a segment,This is example for removal. . So when you search in Word for “.*? “, only FR-FR units will be found, where the text will be replaced with an empty string (
It worked for me though! Thanks!